


未来已来,数语科技数据治理超级智能体来了
十年了,我们一直在做一件事:帮企业把数据管好。从最早给银行建模、搭建数据标准,到后来为制造、能源、运营商做全域数据治理,Datablau数语科技不知不觉已服务了国内超过60%的行业头部客户。说起来,我们在数据治理这个圈子里算得上一个“老兵”。
但说实话,十年做下来,我们心里一直有个坎儿过不去。传统的数据治理太累了,累到我们自己都不好意思跟客户说“这是最先进的”。因为这活儿本质上就是在用人去对抗复杂度,而复杂度的增长是没有上限的。
一、传统治理的三个“坎儿”,我们一个也没绕过去
干过数据治理的人都清楚,这里面有三个迈不过去的坎儿。
第一个坎:不规模化。人力的投入几乎线性增长,很难享受到边际成本递减的甜头。比如给一个几十万字段的应用系统补全中文名称、描述、打业务标签,一两个数据管理员根本忙不过来,加人吧,成本飙升;不加人吧,元数据清一色的全拼英文字段、光秃秃的表结构,无权属、无管家,打标更是“一千个人眼中有一千个哈姆雷特”,认知永远统一不了。曾经一家大行做数据资产盘点,靠几十人手工整理了三个月,结果业务部门一看,说“这标签打的我没法用”。那种挫败感,我们和客户一样深。
第二个坎:不持续。数据治理常常被当成项目来搞,项目一验收,治理基本就停了。人员一旦变动,前任的经验和判断全部带走,治理成果出现断层,没过多久系统里的数据又是一团乱麻。我们见过太多这样的场景:验收时大屏上资产完好、质量得高分,一年后回访,发现新的报表又没人管了,标准也长荒了。这不是客户不努力,是机制没跟上。
第三个坎:不智能。所有的检查和规则都是人预先写死的,系统只能识别显式的格式错误,比如“字段非空”“长度超限”,但根本看不懂隐式的语义。一张表里存着“月收入200000”,你知道它可能缺了个小数点,但规则引擎只觉得格式没问题。更别提主动告诉你“下周业务高峰期,这张表很可能出现超时风险”——传统治理从来都是被动响应,事后灭火。
所以有时候我们内部也在自嘲:传统数据治理的本质,就是拿人肉堆,用人去对抗复杂度,结果注定失败。数据越多,治理越乱,人越累,效果越差。
二、我们开始认真思考:能不能让机器自己治理数据
2024年,大模型开始大量落地,我们发现机器终于能“读懂”语义了。这对数据治理的冲击是根本性的。我们敏锐地意识到,不能再给老平台打AI补丁,而是要重新审视治理的底层逻辑。于是那一年,数语科技开始全面拥抱AI,把大模型能力引入数据治理。
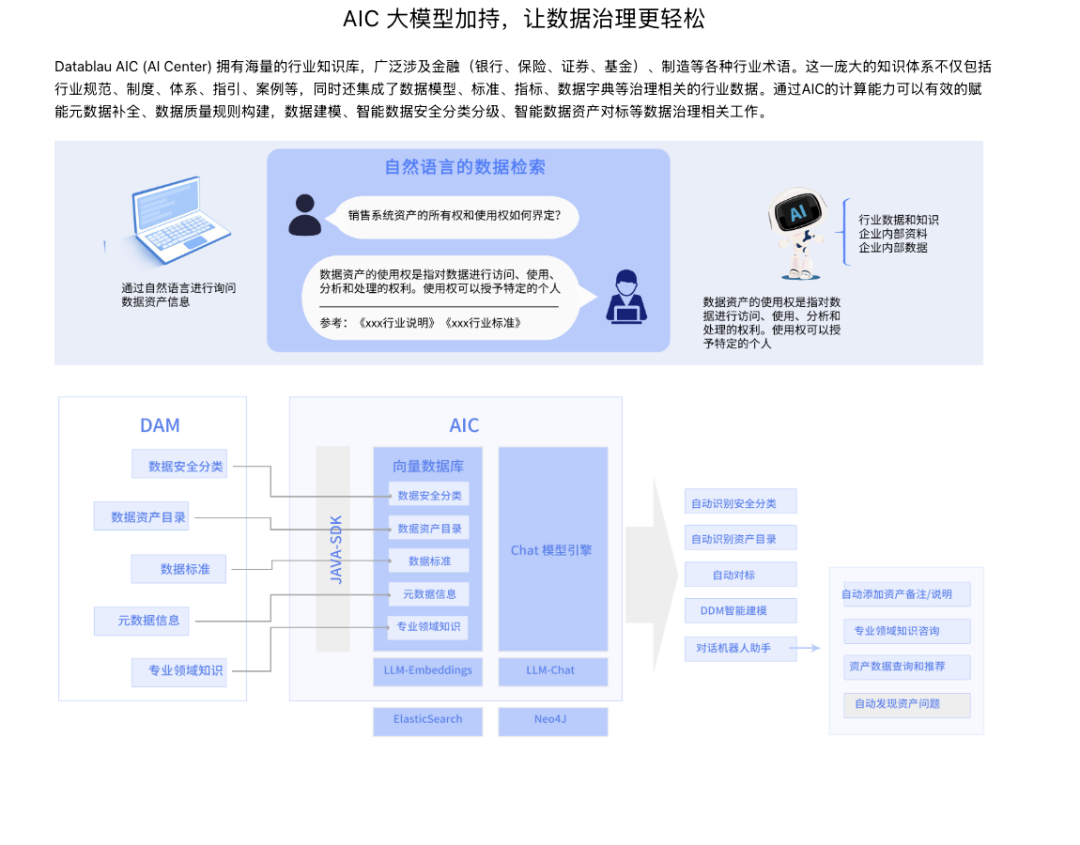
(图:Datablau AIC)
2025年,我们基于MCP协议和自研RAG技术,推出了AIC智能数据治理服务。那是一个初步的尝试,可以用自然语言去探查数据、生成规则、问血缘,甚至做一些自动打标。客户的反响让我们确信,这条路走对了。但AIC还不够——它仍然更像一个能力增强的工具,你说一句,它动一下,依然缺少一种“主动性”。
我们一直在琢磨,有没有可能让治理工作不再靠人驱动,而是变成一个会呼吸、会思考、会自己干活的系统?一个24小时在线的数字化治理专家。
到了2026年的今天,数语科技觉得是时候交出这份答卷了。DIG (数据智能治理)主动数据治理超级智能体,正式发布。
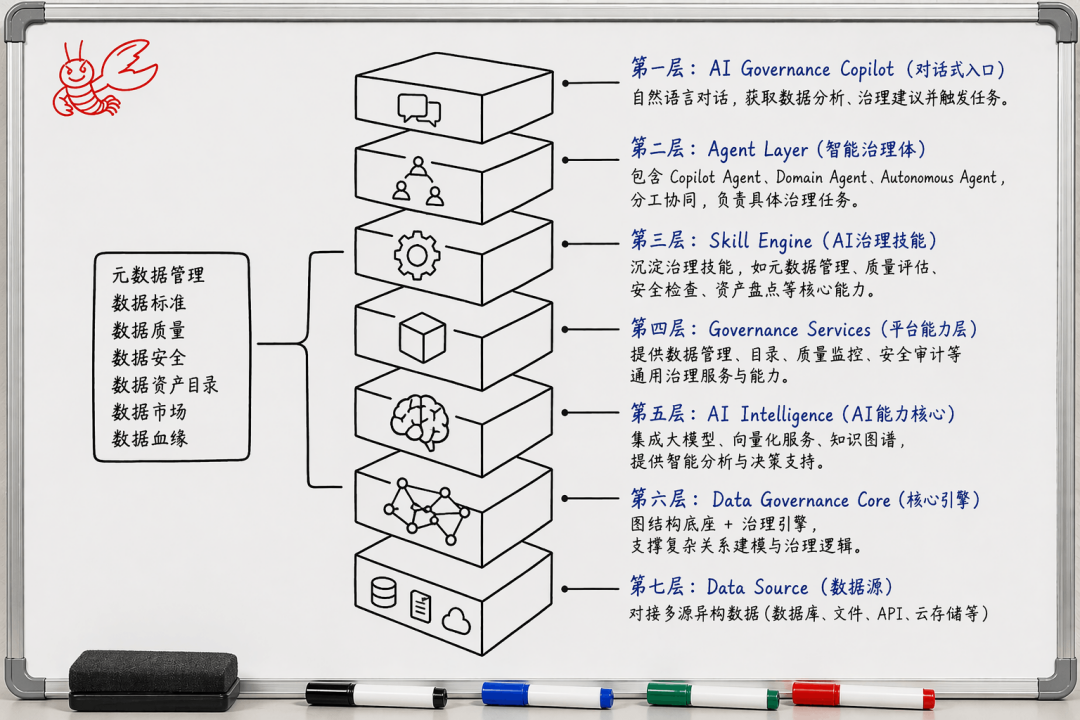
(图:DIG技术架构)
它不是一个加了AI对话的治理平台,而是一个能理解、能执行、能持续进化的超级系统。用一句话说就是:数据治理的终局,不是一套软件,而是一个持续运行的智能体。
三、DIG超级智能体,从“你管它”变成“它帮你管”
既然叫超级智能体,它跟传统平台有什么区别?我们用四个变化就能讲清楚。
1. 对话即治理:菜单消失了
以前做数据治理,你得在一层层的菜单里找功能入口,质量规则在哪里配,数据标准怎么落标,没培训过的业务人员根本找不到北。现在你只需要用自然语言说出意图,系统自动执行。
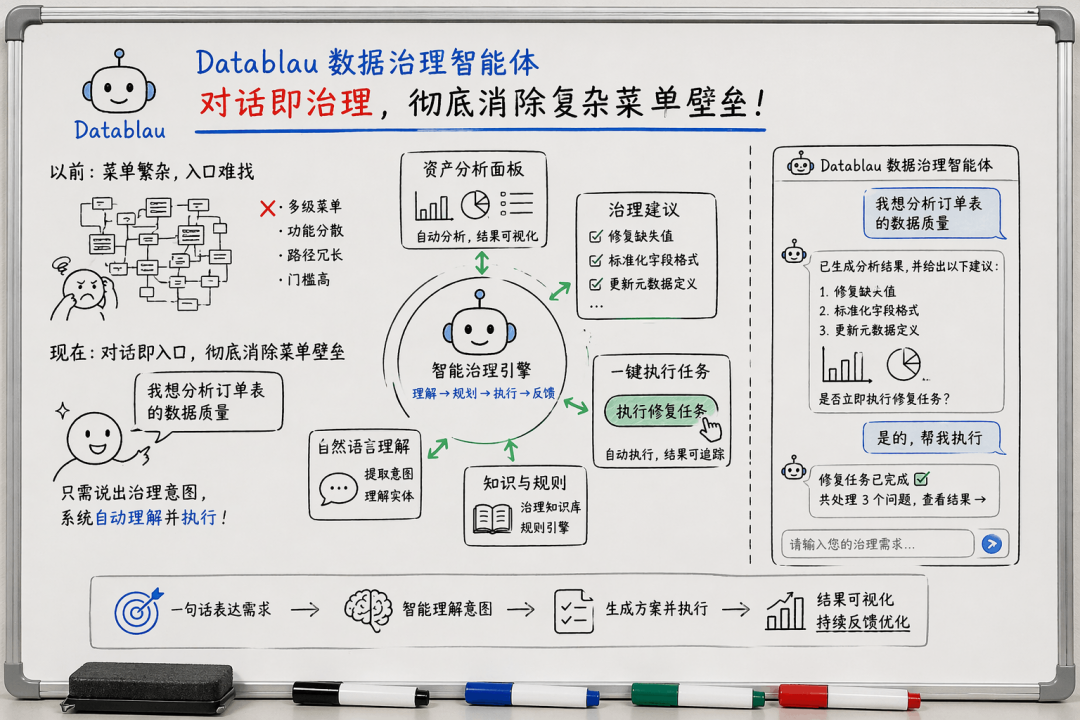
比如你直接对着DIG说:“帮我检查一下订单表最近一周的数据质量”“分析用户表变更会影响哪些下游报表”。DIG马上理解语义,调用元数据、质量、血缘等底层能力,把结果和行动建议推到你面前。这种体验,像在和一个资深的数据架构师对话,你不用关心它调了什么模块,菜单真的消失了。
2. 一体化治理:一个大脑调度所有能力
原来跨模块治理门槛极高,元数据、数据标准、质量、安全分级,这些事儿分散在不同角色手里,协同起来费时费力。DIG厉害的地方在于,它底层自动调度这些能力,你一次对话就能完成闭环。
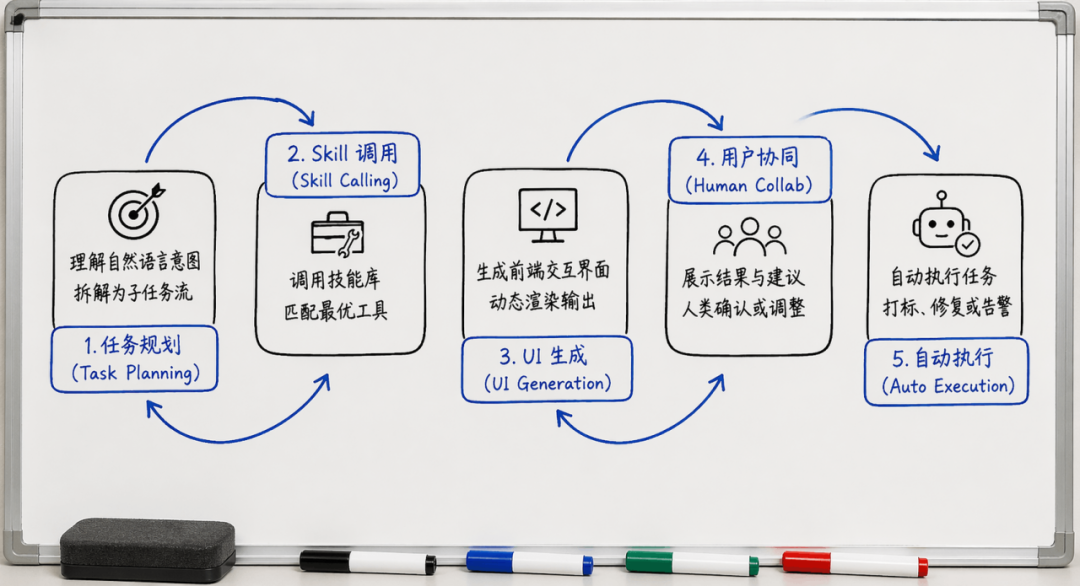
设想你要把“客户信息表”按照金融数据标准落标。以前需要标准管理员、数据拥有者、开发人员反复对齐,最少折腾好几天。现在你告诉DIG,它自己去识别字段映射关系,批量生成标准落标任务,自动核标,生产出一批清晰的改动建议,一并交给人工审核。一个需求,一镜到底。
3. 主动治理:夜班它来值
传统治理的最痛点就是被动。问题不暴露、没人投诉,系统就当什么都没发生。而DIG是7×24小时长驻留运行的,白天随叫随到,晚上自动巡检。
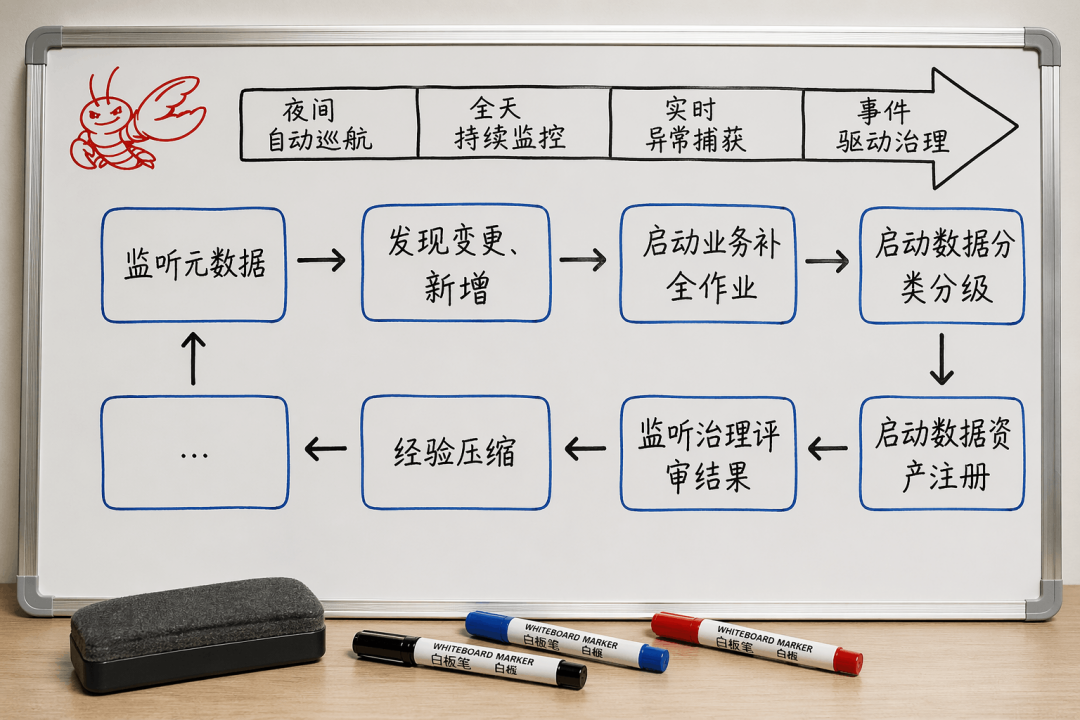
它能趁着夜深人静,扫描全量数据资产,去发现那些悄然出现的质量问题:某个接口字段空值率突然从1%飙到20%,某张核心报表的调度延迟异常,上游业务系统表结构变更导致下游血缘断裂……这些问题一旦被DIG嗅探到,分钟级生成预警和处置建议,第二天一早数据管理员能看到完整的夜巡报告。风险从“事后发现”提前到了“事前感知”。
4. 人机协同进化:越用越聪明
很多人担心AI搞治理,会变成一个黑盒,错都不知道怎么错的。我们在设计DIG之初就定下一个原则:可解释、可干预、可进化。
机器执行治理任务,所有动作都会生成清晰的执行理由和审批页面,人工可以随时修改、通过或拒绝。你的一次次决策,都会沉淀成知识,反哺给智能体。就算组织内负责治理的同事轮岗了,智能体里已经存下了大量的治理经验和判断逻辑,新人进来很快就上手。治理不再因为人的变动而“推倒重来”,人和机器在协同中共同进化。
四、六大场景落地,超级智能体到底能做什么
讲完理念,我们落到具体场景里看一看。DIG在六个核心数据治理场景上,已经打磨出了非常实用的能力。选几个大家感受最深的说说。
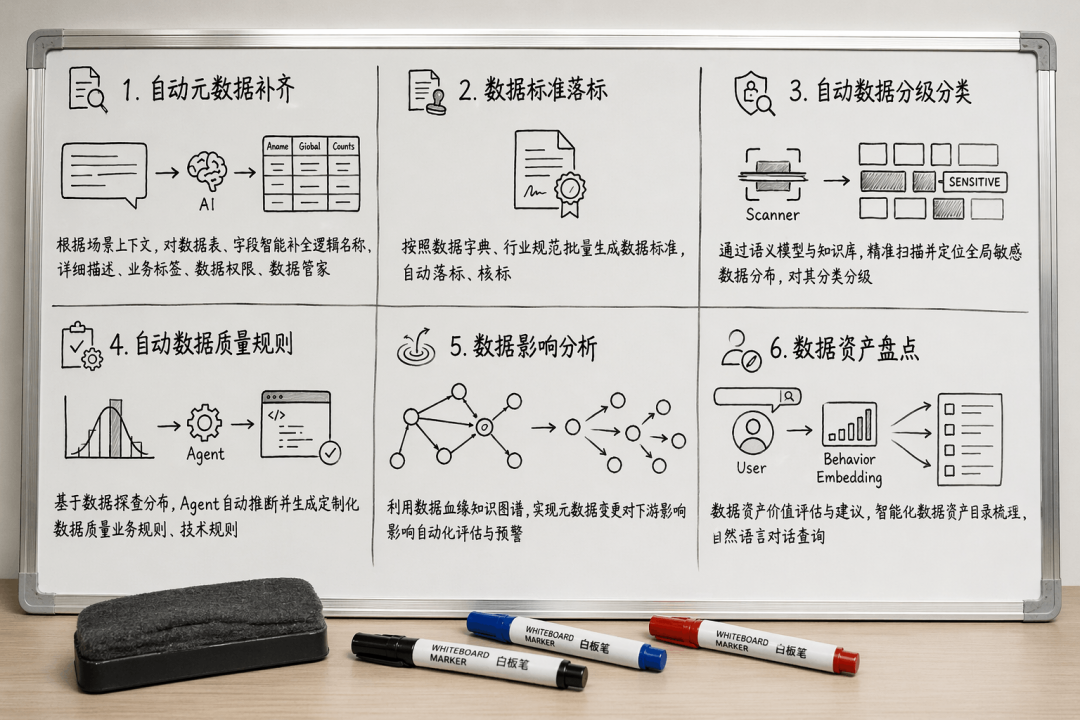
(图:DIG v1.0功能列表)
自动元数据补齐。这是脏活累活的老大难。DIG可以智能补全中文名称、业务标签,甚至推荐数据管家。多张表的相互关联,它从字段名注释、样本数据、上下游关系里推测业务含义,给“cust_id”打上“客户唯一标识”,给“amt”打上“交易金额”,准确率非常高,人只需要抽查确认。在一家DAM老客户的试点中,2天完成了过去需要三个人月才能干完的元数据补全工作,业务标签一致性和可用性反而更好。
自动数据分级分类。数据安全法之下,分级分类成了必答题。可过去全靠人手去逐字段定义“敏感”“内部”“公开”,大企业上千张表搞一年都不稀奇。DIG凭借语义识别,能直接读懂字段里存的可能是身份证号、手机号、银行卡号,自动完成分类分级标记,并且给出定级依据。少数拿不准的,会标上“待确认”推到人工二审。安全合规的效率直接翻了几倍。
自动质量规则生成。DIG不是死板地套用模板,它会先对数据做探查,推断业务规则和技术规则。看到一个“订单金额”字段,会联想到大于0、不为空、波动范围可控等规则;看到“订单状态”枚举值只有“已支付”“已取消”,就帮你生成有效性规则。还能持续监测数据模式,如果某一天突然多出一个“Pending”状态,它会主动提示:“发现新枚举值,请确认是否合法。”
数据影响分析。利用血缘图谱,DIG做到了自动化变更预警。有人想修改一个上游字段的类型,DIG瞬间就能列出下游所有受影响的报表、接口、ETL任务,甚至估算出影响等级。这原本需要一个架构师画半天图才能搞清楚的事,现在几十秒完成,且不会遗漏。
这些都是可以直接兑现业务价值的刚需场景。而更关键的,是这一切都发生在一个透明、可控的流程里。
五、一个真实闭环:从一句对话到一张审批单
我们拿一个典型的治理任务跑一遍,你会更清楚DIG是如何工作的,绝对不是黑盒。
假设某制造企业想完善“供应链域”的数据标准。数据管理员打开DIG对话窗口,用标准化的提示词输入:“请根据供应链行业数据标准,为所有与采购订单相关的表推荐标准映射,并补齐缺失的业务定义。”提示词本身就是精心设计过的,能最大限度降低AI幻觉。
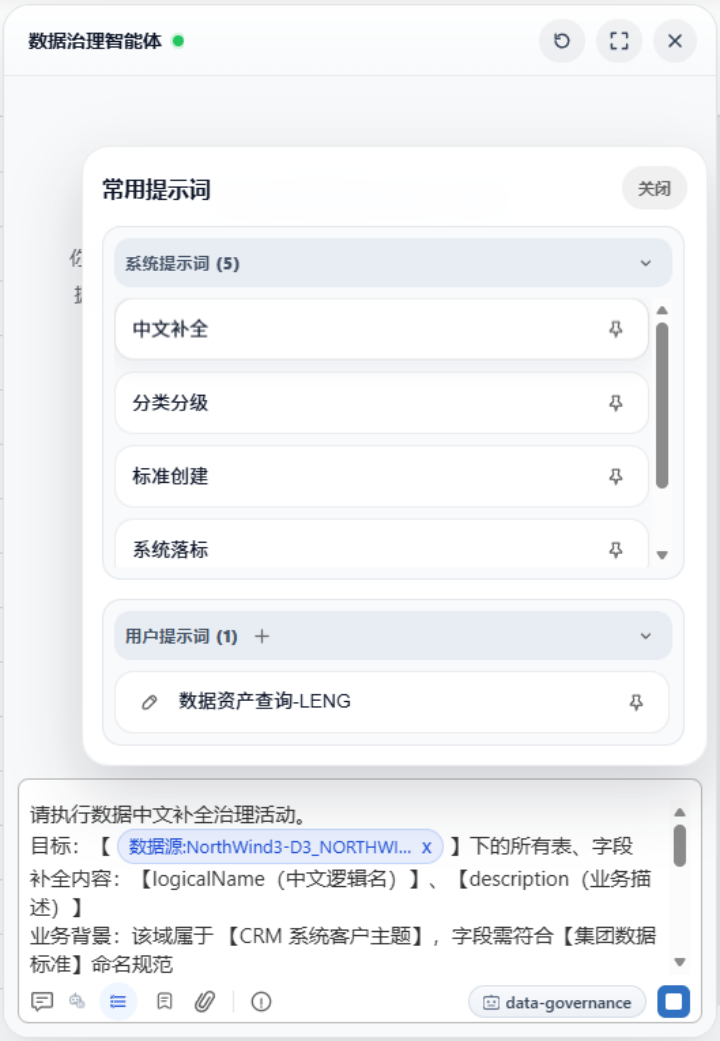
(图:预置治理提示词)
DIG理解意图后,结合当前的治理上下文,会允许管理员通过一个“魔法棒”按钮精准触发AI治理任务。接着自动运行:它检索元数据,发现“采购订单头表”“采购订单行表”等五张核心表,然后逐一将字段映射到标准项,例如把“PO_NUMBER”映射到“采购订单编号”,把“VENDOR_NAME”映射到“供应商名称”;同时发现部分字段缺少中文名称,自动补全建议。
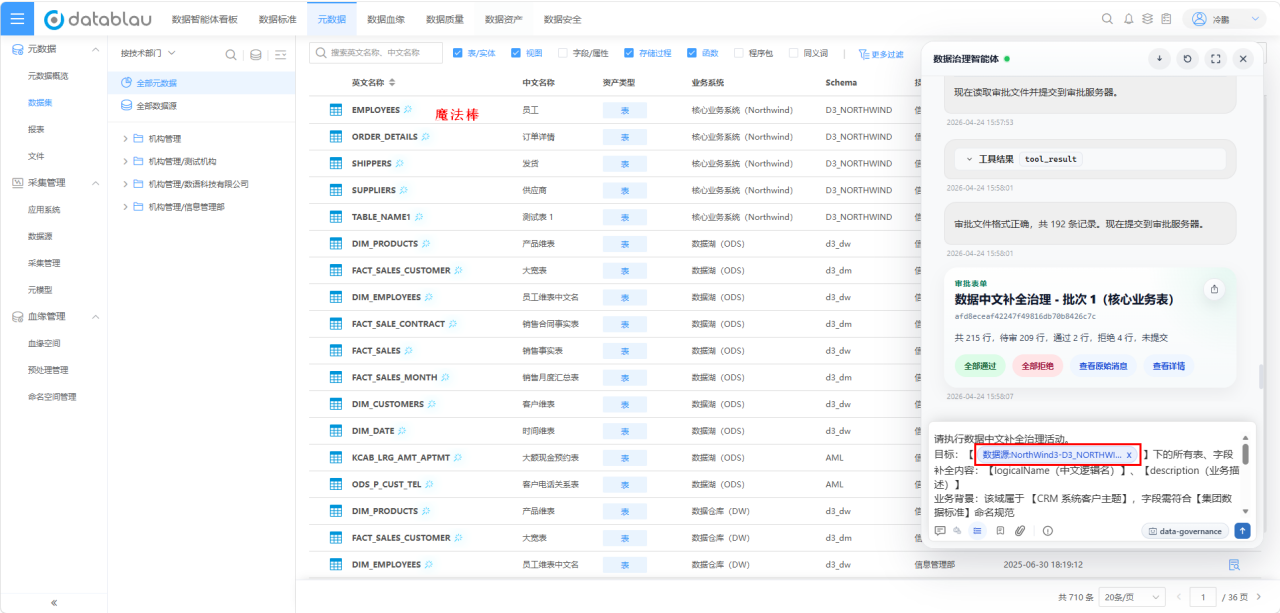
(图:魔法棒激活治理任务窗口)
这些执行结果很快被拼装成一张清晰的结构化审批单,推送到界面。每一项改动都有“AI建议理由”一栏,比如“根据字段取值样例‘PO20231001001’及上下游参照,推断为采购订单编号”。管理员扫一眼,只需修改了一处把“单位成本”错误映射到“标准成本”的情况,纠正后通过审批。整个过程不到三分钟。
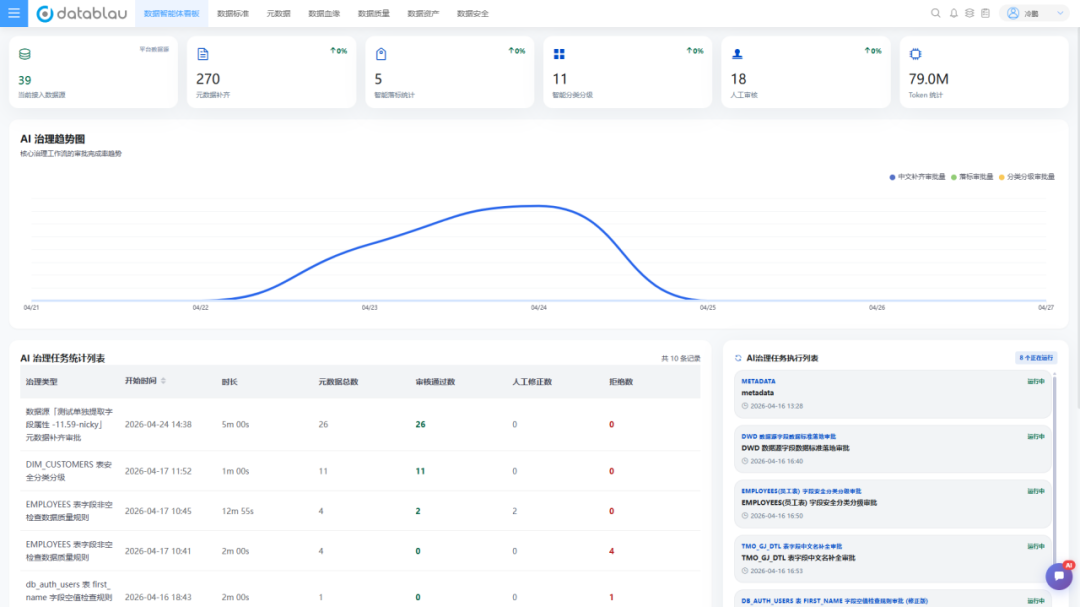
(图:数据治理智能体看板)
任务执行完,仪表盘上会忠实记录下这次对话的Token消耗、运行时长,所有操作全程可追踪。既满足了“AI干重活”的效率,又守住了“人做决策”的底线。这就是我们追求的:不是替代人,而是让人升级为治理的审核者和策略制定者。
六、未来已来,这一次它自己会工作
今天,DIG V1.0正式和大家见面。回头看看,从十年前我们用Excel梳理标准,到后来平台化、自动化,再到今天把治理变成一个活的智能体,我们确实感到,数据治理的变革进入了一个深水区。
超级智能体不是“更好用的工具”,而是一次治理范式的彻底重构。过去我们说“管数据”,未来我们说“交给智能体运行”。企业需要思考的问题变了:不再是“要买多强大的治理平台”,而是“我的治理知识和规则,准备好了交给智能体来延续和进化吗?”
数据治理的终局,真的不是一个打满补丁的平台,而是一个持续运行的智能体系统。作为守在这个行业十年的团队,我们愿意做这个探索者。未来已来,只不过这一次,它自己会工作。


