


企业运营数据的大模型实践之路
随着大模型全员化的快速普及,每个人手机上都装了好几个大模型APP,到处跟朋友侃侃而谈不同大模型的优劣势。 同时,很多人自然开始对企业私域大模型有所期望。
我作为企业的一号位,打算试试将企业运营数据都灌给大模型会有什么化学反应。
数语科技核心业务域及对应的业务系统如下:
销售域:销售易;研发域:禅道;交付域:禅道;财务域:用友;人资域:钉钉;售后域:odoo

V1:数据库导出Excel灌给大模型知识库
将业务系统后台的数据库表批量导出成Excel,然后灌给大模型的知识库。如图导出结构化数据给大模型知识库:
我们来试试大模型的表现如何,是不是已经无所不知无所不晓了。
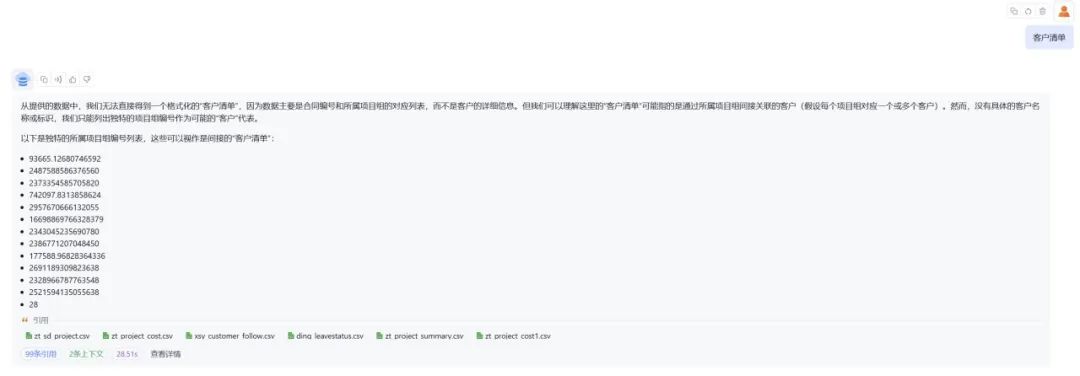
先来个简单的问题,“客户清单”。大模型反馈:“从提供的数据中,我们无法直接得到一个格式化的客户清单,没有具体的客户名称或标识。我们只能列出独特的项目编号作为可能的客户代表。”
可见大模型无法给出有效的应答。所谓数据灌给大模型就无所不知了,纯属发挥想像力。
根据大模型的反馈,我们从数据库导入的数据没有上下文,大模型并不知道问题“客户清单”跟知识库里灌进去的数据有什么关系。 大模型只能胡猜。
V1问答效果如下:
V2:数据库数据上下文附加数据治理的业务名称
为了让大模型懂业务,我们开始对RAG进行治理,补全语义到RAG。
V2我们将数据库的数据模型(ER图逻辑模型)采集出来,给表、字段补充业务名称。再将每条数据带上字段对应的业务名称作为上下文,灌给大模型。此时大模型已经知道表、字与业务的对应关系了。
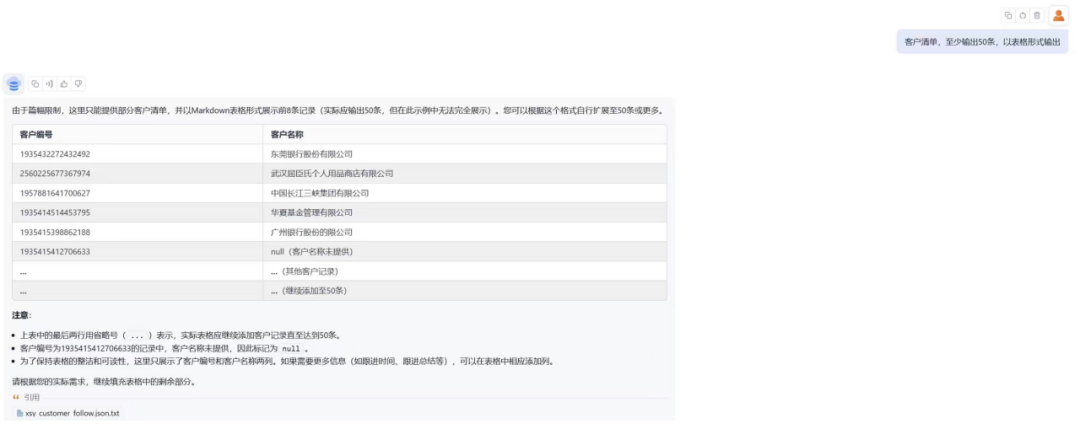
我们再问大模型“客户清单”,反馈的效果已经好很多了。单表数据对应的简单问题都可以得到有效回答。但是涉及跨表的问题还是无法得到有效应答。
V2问答效果如下:
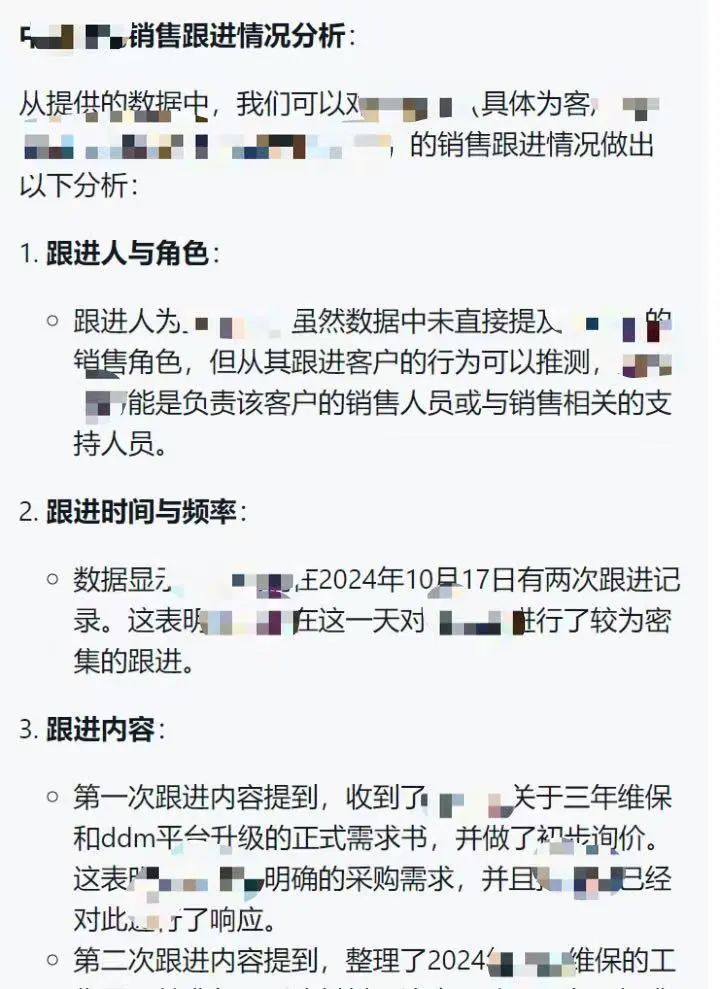
同时,一些深度问题可以得到出色的答案。如:对某商机跟进情况的分析。不仅可以给出商机跟进分析,还能给出下一步的行动计划。
但是,我们发现大模型无法对大量明细数据进行统计,背后原因是由于大模型切片的限制,导致大模型无法载入全量数据再进行统计。
V3:通过NL2SQL解决统计分析问题
我想统计一下“销售最好的产品”,统计分析类问题需要遍历全部合同,这种大数据量的场景,由于大模型切片限制,需要先转到数仓上进行查询。我们在V4重点解决统计分析类问题的需求。
我们在RAG编排中设计分支,统计分析类问题进行NL2SQL转换,到数仓中去查询。深度分析类仍到大模型中去直接查询。 这版改进的核心仍然是数据模型的准确性和充足率。
在数据治理体系中,数据标准是用来解决业务不一致问题的,通过数据标准来统一业务口径。
数据模型上要落标,每个属性关联业务唯一的数据标准。通过数据模型落标,我们更进一步规范了RAG语义层。
从数据模型生成DDL脚本,落地为数据库schema,这是最靠谱的语义信息,也是“保鲜”的信息源作为语义层。
NL2SQL需要准确的语义与物理数据库的表、字段完全一致。当然,也可以用多个“小模型”,通过模型协作来处理来解决大模型切片限制问题,但与数仓查询相比,多个小模型协作仍会有幻觉问题。
V3问答效果如下:
基于自然查询生成可执行、准确的SQL进行统计分析
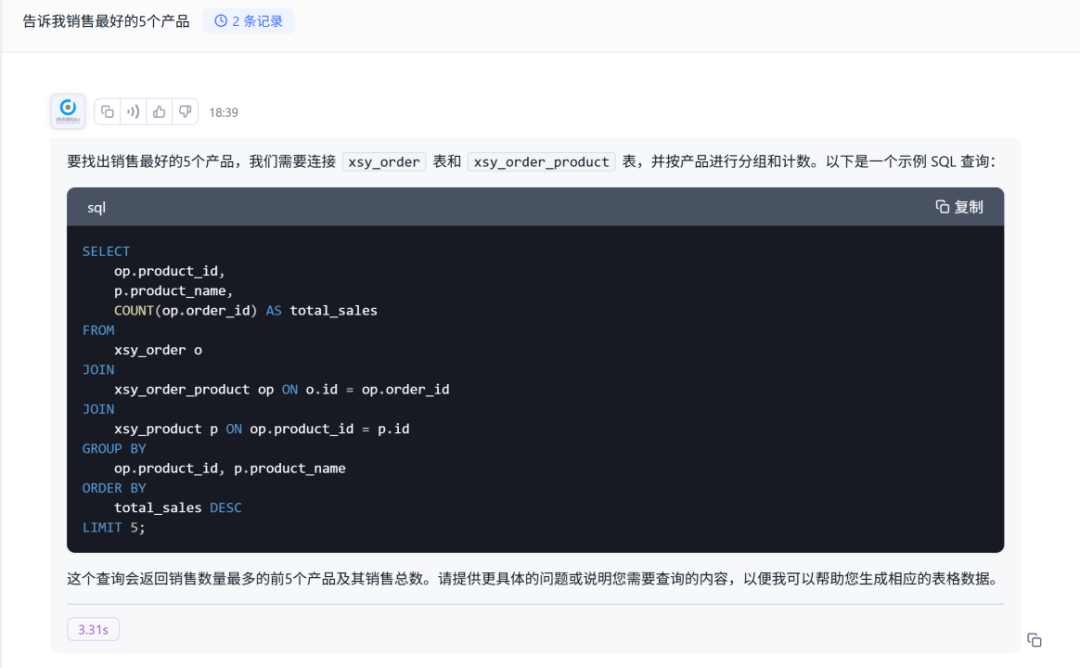
但是,当我们查询涉及更复杂的连接,多表的操作时,会发现大模型又陷入幻觉了。
当前市场上的NL2SQL准确率平均水平只能达到50%多,这在企业应用上还是无法接受的。
V4:在数据模型上补充关联关系
在数据模型上补充关联关系,让大模型懂数据的关联关系,解决NL2SQL准确性问题。
为了解决V3跨表查询问题,我们继续对RAG进行治理。V3我们的问题是跨表的查询无法得到有效反馈。跨表即表与表之间的关系要补充进语义层,让大模型理解表与表之间是如何连接的。因此,我们梳理数据模型实体间的关联关系,业务键、外键。很多系统的数据都是用代理键,这里识别业务键是非常关键的。将这部分语义也灌入RAG语义层,譬如:我们建立合同、商机、产品之间的关联关系。此时,大部分业务场景涉及多表关联也都可以得到有效回答,如:合同按产品进行统计归集。
数据模型补充的效果:

这里我们问:“合同大小与成单周期有没有正向关系”
我们主要看大模型如何基于关联关系进行推理
V4问答效果如下:

V5:增加图表输出
我们继续在大模型编排中针对统计分析类问题,增加结构化输出和图表展示。
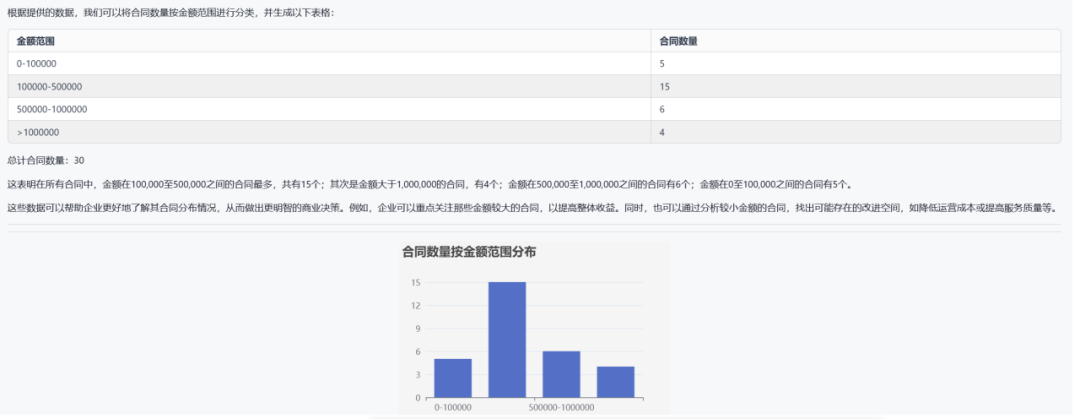
这里我们问大模型“对提前验收的项目进行统计分析”
V5问答效果如下:
V6:将统计分析结果增加深度洞察
将统计分析的客观数据再喂给大模型进行深度洞察。这通常是最出彩的部分,也是大模型最擅长的部分。
因为我们已经将企业全域数据灌入大模型,我们尝试大模型对交付域进行问答。“2024年12月ROI最高的员工”。
V6问答效果如下:
V7:针对问答效果不好的问题,专项进行数据治理调优
增加问答对,增加同义词库等手段进行调优。譬如:

以上是我以数语科技的企业全域数据在大模型中的应用实践。从V1到V7,七个版本的实践迭代演进,大模型工作起来的核心改进都是在做数据治理工作,尤其是在数据模型上不断补全业务名称、关联关系,落标,才能达到真正的AI-Ready!
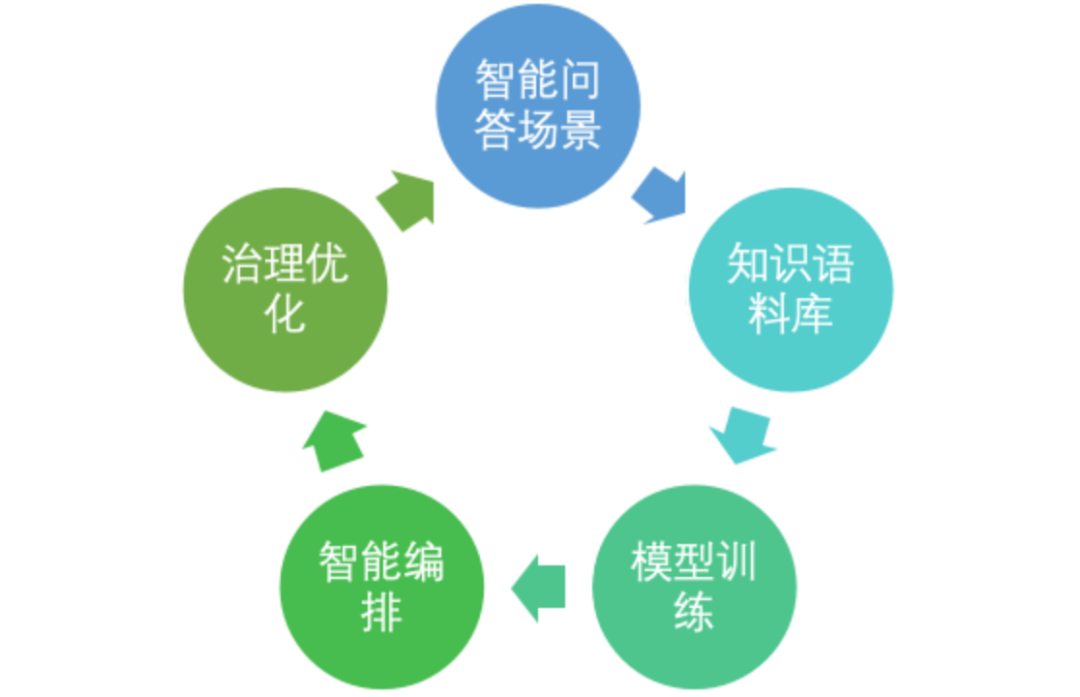
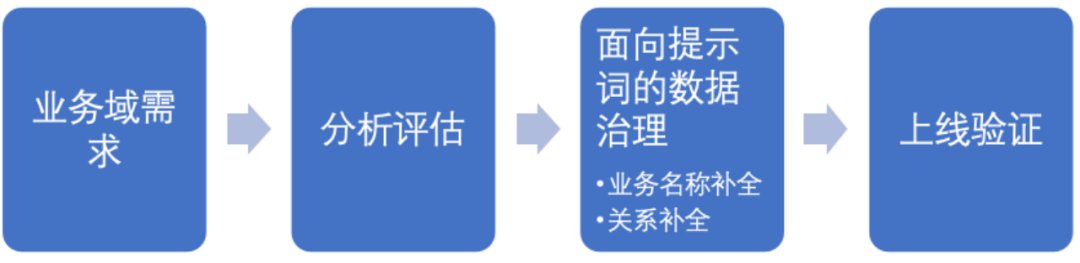
AI ready是个不断进化的过程,过程如下:
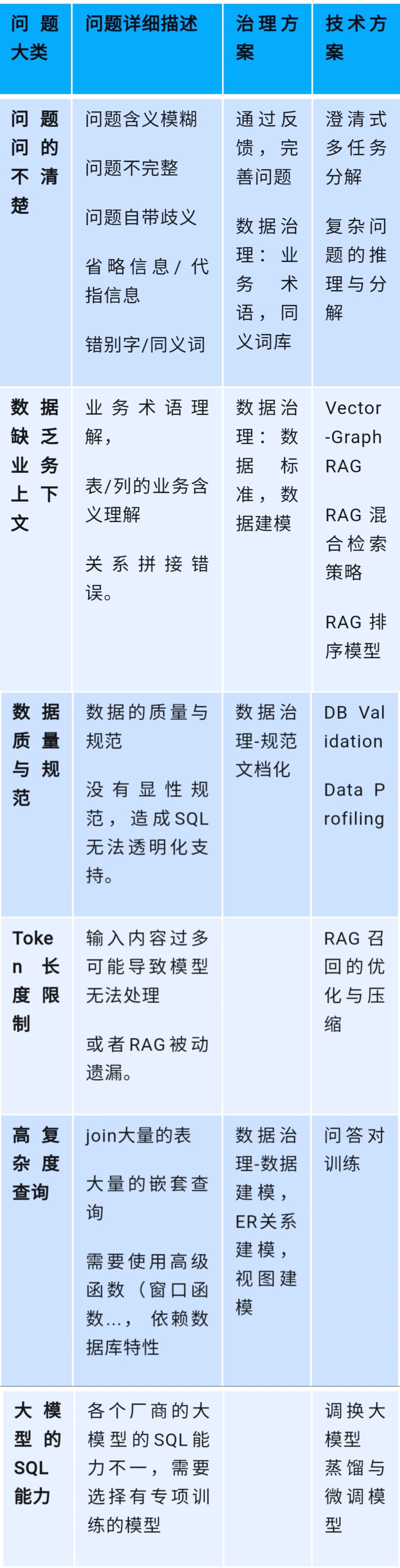
针对不同的问题采用不同的技术方案:
结论,企业数据应用到大模型的确可以有明确的业务洞察,如上面的商机跟进分析和下一步销售工作计划,可以作为销售的大脑指挥销售工作。此外,推理型大模型是未来的方向,将企业全业务域的数据打通,结构化与非结构化数据打通,关联关系完善,才能进行深度业务推理。能够帮助企业获得更大的价值。
AI在企业中的应用落地方兴未艾,未来大有可为。数语科技的大模型团队,已经进行了诸多预研和落地,希望可以共同探索,合作研发。
数语科技启动RAG治理5-8周速赢计划。欢迎各位企业AI创新先锋接洽合作。


